Tuesday, November 30, 2010
Wednesday, November 24, 2010
Tuesday, November 23, 2010
SOAP
SOAP consists of three components:
- Envelpe
- A set of encoding rules
- A convention for reresenting remote procedure calls
CoolTuts - Java - Exceptions
To handle an Exception, enclose the code that is likely to throw an exception in a try block and follow it immediately by a catch clause.
Exception handling is a very powerful tool, you can use it to catch and throw exceptions and thus group all your error handling code very well and make it much more readable in larger more complex applications. After the try section there must exist one or more catch statements to catch some or all of the exceptions that can happen within the try block. Exceptions that are not caught will be passed up to the nexxt level, such as function that called the one which threw the exception, and so on.
try
{
// code that might fail
}
catch(Exception1ThatcanHappen E)
{
}
catch(Exception2ThatcanHappen E)
{
//things to do if this exception was thrown.
}
CoolTuts - Java - Interfaces
Example:
interface counting
{
abstract void increment();
abstract int getValue();
}
A class that implements a particular interface must declare this explicitly:
class ScoreCounter implements counting{
....
}
CoolTuts - Java - Arrays
Declaring Arrays
When you declare an array variable you suffix the type with [] to indicate that this variable is an array.
Example: int [] k;
Allocating Arrays
When we create an array we need to tell the compiler how many elements will be stored in it. The numbers in the bracket specify the dimension of the array.
Initialising Arrays
Individual elements of the array are referenced by the array name and by integer which represents the position in the array. The number we use to identify them is called subscripts or indexes in a array. Subscripts are consecutive integers beginning with 0.
CoolTuts - Java - Methods
You can write and call your own methods too. Methods begin with a declaration. Method consists of the following parts.
- Access Specifier public: This method can be called from anywhere. private: This method can be called or used within the class where it is defined. protected: This method can be used anywhere within the package in which it is defined.
- Static or Dynamic method Static methods have only one instance per class rather than one instance per object. All objects of the same class share a single copy of a static method. By default methods are not static.
- Return Type
CoolTuts - Java - Comments
- // compiler ignores everything from // to the end of the line.
- /* text*/ compiler ignores everything from /* to */
- /** documentation */ compiler ignores this kind of comment, just like it ignores comments that use /8 and *// The JDK javadoc tool uses doc comments when preparing automatically generated documentation..
Monday, November 22, 2010
Bug Life Cycle
Each bug has the status, which indicates the position of the bug in the life cycle. An Issue starts with "Open" status, then progresses to "Resolved" and then "Closed".
Following are the status of the bugs:
- Open
- In Progress
- Resolved
- Reopened
- Closed
An issue can be resolved in many ways.
- Fixed
- Won't Fix
- Duplicate
- Incomplete
- Can't Reproduce
Priority: Indicates its relative importance.
- Blocker - Highest Priority - Indicates that this issue takes higher precedence over all others.
- Critical - Indicates that this issue is causing a problem and requires immediate attention.
- Major - Indicates that this issue has significant Impact
- Minor - Indicates that this issue has relatively minor impact.
- Trivial - Lowest Priority
Wednesday, November 17, 2010
Components of Selenium
Selenium-IDE has a recording feature, which will keep account of user actions as they are performed and store them as a reusable script to play back.
It also has context menu integrated with the Firefox browser, which allows the user to pick from the list of assertions and verifications for the selected location.
Exported test can be run in any browser and any platform using "selenium remote control".
Selenium RC: Selenium-RC provides an API (Application Programming Interface) and library for each of its supported languages: HTML, Java, C#, Perl, PHP, Python and Ruby.
Allows playing of scripts which are exported to different platform or OS.
This ability to use Selenium RC with a high level languague to develop test cases also allows the automated testing to be integrated with the project's automated build environment.
Selenium Grid: Selenium-Grid allows the Selenium-RC solution to scale for test suites or test suites to be run in multiple environments.
With selenium-Grid multiple instances of Selenium RC are running on various operating system and browser configurations, each of these when launching register with a hub. When tests are sent to the hub they are then redirected to an available Selenium-RC, which will launch the browser and run the test.
This allows running the tests in parallel, with the entire test suite theorietically taking only as long as to run as the longest individual test.
Tuesday, November 16, 2010
Open an XML File using Internet Explorer
- Open the Notepad and type in the following
<first>John</first>
<last>smith</last>
</name>
- Save the document to your hard drive as name.xml. If you are using Windows XP, be sure to save as Type drop-down to All Files.
- You can open the file in Internet Explorer.
Friday, November 12, 2010
CoolTuts - JavaScript - Variable
var strname = some value
Scope of the Variable
- When you declare the variable within a function, the variable can only be accessed within that function.
- When you declare the variable outside the function, all the functions on your page can access it.
- The life time of these variables starts when they are declared, and ends when the page is closed.
CoolTuts - QTP - Recovery Scenario Manager
If you can predict that a certain event may happen at a specific point in your test, it is highly recommended to handle that event directly within your test by adding steps such as if statements or optional steps, rather than depending on a recovery scenario. By default, recovery scenario operation are activated only after a step returns an error.
Creating a Recovery Scenario File
Go to Resources > Recovery Scenario Manager.

Click on New Scenario Button

Click on Next. Select Trigger Event Dialog Box opens.

This screen displayed in the wizard depends on which of the following trigger types you select.
1. Popup Window
2. Object State
3. Test Run Error
4. Application Crash

Using this option (Window title and/or Window text) instructs QTP to identify any pop-up window that contains the relevant title and/or text. Click on Hand button and show the popup window which is popup.
Click on Next Button.

Using this we can select an object for which we have to create recovery. Click on Hand button and show the object
Click on Next Button

Select the type of error for which you want to create recovery and click on Next.

Running process displays all application processes that are currenly running. The processes list displays the application processes that will trigger the recovery scenario if they crash.
Click on Next Button to the Recovery operations Screen and again click on next for recovery operations.

Select the type of recovery operation and click on next.
Keyboard or mouse operation
QTP simulates a click on a button in a window or a press of a keyboard key. Select this option and click on Next to continue to the Recovery Operation.
Close application process
QTP closes specified processes. Select this option and click on Next to continue to the Recovery Operation - Close Processes Screen.
Function call
QTP calls a VBScript function. Select this option and click Next to continue to the Recovery Operation - Function Call Screen.
Restart Microsoft Windows
QTP restarts Microsfot Windows. Select this option and click Next to continue to the Recovery Operations Screen.

If you select function call then this screen will be displayed. By clicking on browse button select the recovery function, if it already available. Else Select Define new function to define now.
Click on Next for Post Recovery Operations.
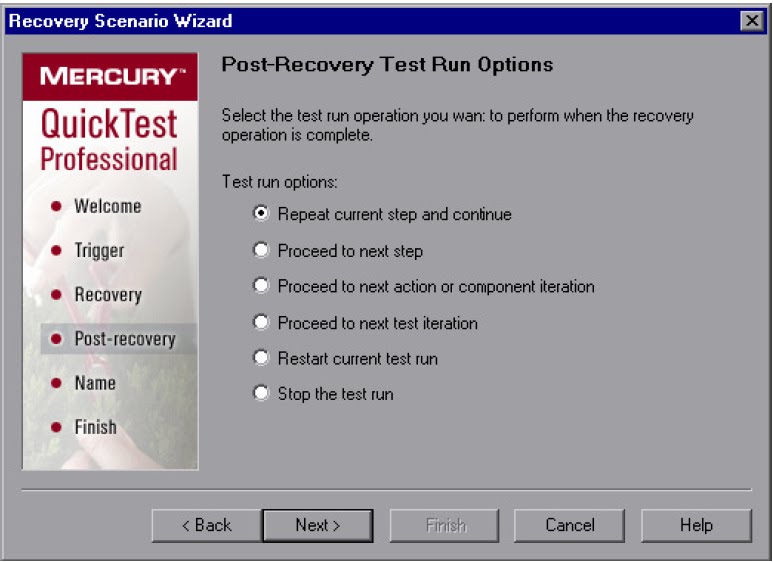
Post Recovery Operations
Repeat current step and continue: Repeat the current step that QTP was currently running when recovery scenario is triggered.
Proceed to next step This skips the step that QTP was running when the recovery scenario was triggered
Proceed to next step or component Goes to next action iteration after completion of recovery operation
Proceed to next test iteration Goes to next test iteration after completion of recovery operation
Restart current test run To restart the testrun after completion of recovery operation
Stop the test run To Stop the Entire Test run.

Enter a name and a textual description for your recovery scenario, and click Next to continue to the completing the Recovery Scenario Wizard Screen.

In the Completing the Recovery Scenario Wizard screen, you can review a summary of the scenario settings you defined. You can also specify whether to automatically associate the recovery scenario with the current test and/or to add it to the default settings for all new tests.
Click on Finish, save the scenario and Scenario File. If you want to use this scenario for any test you need to associate the scenario to a test.
CoolTuts - QTP - Output Values
You can output the property values of any object. You can also output values from text strings, table cells, databases and XML Documents.
Wednesday, November 10, 2010
CoolTuts - QTP - Recording QTP Scripts

CoolTuts - QTP - Information Pane
To show or hide information pane, choose View > Information Pane
When you switch from the Expert View to the Keyword View, QuickTest automatically checks for syntax errors in your script, and shows them in the Information pane.
Monday, November 8, 2010
CoolTuts - JavaScript - Event Handlers
Every element on a web page has certain events which can trigger JavaScript functions. We define the events in the HTML tags.
Event handlers are not added inside the <script> tags, but rather, inside the html tags, that execute the JavaScript when something happens, such as pressing a button, moving mouse over a link, submitting a form.
Basic syntax of event handlers is:
name_of_the_handler = "JavaScript code"
Example:
<a href="www.google.com" onClick="alert("hello")">Google</a>
when user clicks on the link, it will prompt an alert box before being taken to Google.
Some of the most commonly supported eventhandlers:
onClick -- Invokes JavaScript upon clicking (a link, or form boxes)
onLoad -- Invokes JavaScript after the page or an image has finished loading
onMouseover -- Invokes JavaScript if the mouse passes by some link
onMouseout -- Invokes JavaScript if the mouse goes pass some link
onUnload -- Invokes JavaScript right after someone leaves this page
OnClick Event Handler: OnClick event handler is executed when an element is clicked. It can only be added to visible elements on the page such as <a>, form buttons, check boxes, a DIV etc.
OnLoad Event Handlers This is used to call the execution of JavaScript after a page, frame or image has completely loaded.
onMouseover, onMouseout
onMouseover and onMouseout event handleres can be added to visible elements such as a link (<a>), DIV, even inside the <BODY> tag, and are triggered when the mouse moves over and out of the element.
onMouseover and onMouseout events are often used to create "animated" buttons.
onUnload Event Handler onunload executes JavaScript immediately after someone leaves the page.
Applicability of Event Handlers
onAbort ---<img> tags
onBlur --- window object, all form objects
onClick---Most visible elements such as <a>, <div>, <body>
onChange---Use this to invoke JavaScript if mouse goes pass some link
onError --- Text fields,Text Areas
onFocus---Most visible elements such as <a>, <div>, <body>
onLoad---<body>, <img>, and <frame>
onMouseover---Most visible elements such as <a>, <div>, <body>
onMouseout---Most visible elements such as <a>, <div>, <body>
onReset --- <form> tag, triggered when the form is resent via <input type="reset">
onSelect --- Elements with textual content. Most commonly used inside text fields and text areas
onSubmit --- <form> tag, triggered when the form is submitted
onUnload --- <body>---Most visible elements such as <a>, <div>, <body>
The Onload event is often used to check the visitor's browser type and browser version, and load the proper version of the web page based on the information.
onFocus, onBlur and onChange
These events are often used in combination with validation of form fields.
OnSubmit
onSubmit event is used to validate All form fields before submitting it.
CoolTuts - JavaScript - Creating Interacitve Boxes
- window.alert()
- window.confirm()
- window.prompt()
window.Alert()
This commands pops up a message displaying whatever you put in it. User will have to click "OK" to proceed.
window.confirm()
This commands is used to confirm a user about certain action, and decide between two choices depending on what the user chooses. User will have to click on "OK" or "Cancel" to proceed.
window.prompt()
This command is used to allow a user to enter something and do something with that information. User will have to click on "OK" or "Cancel" to proceed after entering an input value.
CoolTuts - JavaScript - Getting Started
JavaScript is a language of objects, and all objects have both methods and properties. "Document" is just one of the many objects. It is the object that controls the layout of a webpage-background color, text, images etc.
Document Object has the following properties:
bgColor
lastModified
referrer
fgColor
CoolTuts - JavaScript - Introduction
You can only create Static webpages, using HTML. By using JavaScript, with HTML you can convert the webpages to Dynamic webpages.
Java is more powerfull language compared to Javascript. You need to compile java program before you run it, whereas with JavaScript, no compilation is needed. JavaScript is typed and saved in text editor and it runned using the Browser.
Every one can use JavaScript without purchasing a license.
A JavaScript is usually embedded directly into HTML pages.
Test Estimates
There are two types of Test Estimation Approaches
1. Bottom-up Estimation
2. Top-down Estimation
Top-down Estimation
In this approach the effort (cost) of the whole project is estimated first. The estimation of the overall effort is made based on the type and scale of the project and on similar projects that were carried out before. The estimation for phases or activities or subsystems is calculated as a percentage of the whole. Past data and present project characteristics are used to adjust the estimate to meet project specific situation
Bottom-up Estimation
First the size, effort and schedule of each phase or activity and work products produced is estimated. The effort (cost) of the total project is calculated by aggregation. This approach is suitable for projects where a detailed knowledge of the product to be built and the project specific process and complete work breakdown structure is available. Past data and present project characteristics are used to adjust the estimate to meet project specific situation.
"Effort" can be computed using the following simplified relationship:
Effort = Size * Productivity
Where "size" is the estimated size (KLOC or FP) of the current project
"Productivity" parameter (Person Months per KLOC)
Size Estimation
The software size is estimated in terms of "Lines of Code" (LOC) or "Function Points" (FP). LOC or FP data is used in two ways during project estimation:
1) As an estimation variable that is used to "size" each element of the software
2) As baseline metrics collected from past projects and used in conjunction with estimation variables to develop cost and effort projections. Apart from LOC or FP component measures like classes or objects can also be used.
Some times the software size is estimated in terms of physical size units, such as:
• Number of screens and menus
• Number of reports
• Number of forms
• Number of pages of documentation
• Impacted lines of code
• Impacted business processes
Estimating Lines of Code (LOC)
LOC measures are programming language dependent. A software product may consist of developed code, modified and reused code, and commercial off the shelf software code.The size of developed code, modified and reused code and commercial off the shelf code need to be estimated separately. The nature of effort required for developing new code is different from that of modifying and integrating reused code or integrating with commercial off the shelf software.
The greater the degree of partitioning, the more likely that reasonably accurate estimates of LOC can be developed.
Estimating Function Points
Function Point method is independant of technology.
Effort Estimation Using Simple Estimation Relationships
In this method of estimation data from past projects (similar projects) is used to establish simple equation for estimation of effort. The following metrics from the past projects may be used for estimation:
- Effort (person-months) per KLOC (or FP)
- Documentation (Pages) per KLOC (or FP)
- Defects (Delivered or In-process) per KLOC (or FP)
The software product size specified in KLOC or FP may be used. The size estimate could be a one-point estimate (most likely) or could be based on a three-point estimate (Optimistic, Normal (most likely), and Pessimistic). Usage of three-point estimate for size would give a range of values and also the "Expected Value" for effort. Using simple estimation relationship effort can be computed in the following way:
- Identify relevant past projects and collect their metrics data
- Analyze the metrics and arrive at a common value (simple average or weighted average) across the projects for each metric.
- Multiply size by effort per KLOC metric value to get nominal effort for the new project
- Multiply size by documentation (pages) per KLOC to get size of documentation
- Multiply size by defects (delivered or in-process) per KLOC to get projected defect values
Effort Estimation Using Wideband Delphi Method
This method is suitable for new projects where no past project data is available. Using this method effort can be estimated in the following manner:
- Identify a team of experts (resources with relevant application and technical skills and knowledge) and a facilitator to facilitate the estimation process
- Provide the software product details and other technical documents to the experts
- An overview meeting is conducted by the facilitator to discuss the project scope, work involved, assumptions and estimation issues.
- Each expert prepares a three-point size estimate (LOC or FP) using the size estimation procedure explained earlier. The expert also prepares justification for arriving at the estimation
- Based on the size estimate the effort is also estimated by the expert using simple estimation relationship or by judgment using personal experience
- Suitable effort adjustment buffer % of effort) is to be provided to take into account complexities and uncertainties associated with product, platform (technology), personnel and project.
- The estimates are given to the facilitator, who tabulates the estimation data and the justifications given by each expert and computes the median value and range of estimates
- The tabulated results and justification report given to each expert provides details of median estimate, range estimates and the concerned experts estimate. The other expert's estimates are also given in the report anonymously.
- The experts study the results and justifications and meet to discuss in detail their estimates
- Based on the deliberations and new insight each expert may revise his estimate
- The process iterates again till all experts agree to a common three-point estimate
- Complexity is defined as High, Medium and Low based on the requirements of the project and a. Number of technologies involved, b. Familiarity of team with technologies, c. Bleeding edge or well established technology and d. Number of technical interfaces/services based on this complexity levels to be defined like : High, Medium and Low
Effort Estimation Using Analogy
Analogy method assumes that some resemblance and commonality exist between the new project and past project(s). This method can be used for size and effort estimation in the following manner:
- Study the project scope and details of the new project
- Identify at least one project executed in the past that is analogous to the new project
- Analyze the new and old projects software product to arrive at common features and differences between them
- Obtain the metrics data of the selected past project on size, effort, defects, etc.
- Estimate size (LOC or FP) of the new software as per the size estimation method
- Specify optimistic, normal, and pessimistic size of the components (Use the Component Size and Complexity Entry form in QMS to record the size)
- Specify optimum, normal, and pessimistic effort required for coding of each software component. Coding involves code development, compilation, and code review tasks only.
- Identify and provide for contingency to account for impact of risks on software size.
- Identify and take into account inclusion /integration of off-the-shelf/reusable components and its impact on software size.
- Develop expected value of total size and effort for coding
- Provide suitable adjustment buffer (% of effort) to take into account complexities and uncertainties associated with product, platform (technology), personnel and project.
- Obtain the phase / activity wise effort distribution (%distribution) from the selected past project.
Project Schedule is calculated using:
Schedule= Allocated Effort / (8 * No. of resources)
Estimation for Bug fixing
Many times bug fixing may involve changing (adding/deleting/modifying) few lines of code. The size of the change may be trivial. Hence size estimate is not required. However the effort required for research activity and solution development may be very high. Techniques such as simple estimation relationship can be used for effort estimation.
QA Project Effort = (Test planning effort) + (Test design effort) + (Test design maintenance effort) + (n * software build test effort)
Test Design Effort = No. of test cases * Effort required per test case
Thursday, November 4, 2010
CoolTuts - QTP - Object Identification
Object Identification in Running session
In Normal or Low level recording QTP stores object information in the object repository. QTP script consists of the object class, object name, operations, and values.
While Running the scripts QTP will see the class, object name in the script and it searches the same object name in the object repository. If that name exists in the object repository then QTP will identify the object in the application using recorded properties in the object repository.
To change the object identification in QTP, select
Tools > Object Identification
Using Object Identification, you can
1. Configure the properties for each class
2. Selecting the Ordinal Identifier
3. Configure the smart identification
4. Creating user defined classes
In object Identification Dialog box you can find list of classes. For every class you can find pre-configured Mandatory and assistive properties.
- Mandatory properties -- Properties that QTP always learns for a particular test object classes.
- Assistive properties --- Properties that QTP learns only if the mandatory properties are sufficient to create a unique description. If several assistive properties are defined for an object class, then QTP learns one assistive property at a time and stops as soon as it creates a unique description for the object.
- Ordinal Identifier--- If the combination of all defined mandatory and assistive properties is not sufficient to create a unique test object description, Quick Test also records the value for the selected ordinal identifier.
There are two types of ordinal identifiers:
- Index - indicates the order in which the object appears in the application code relative to other objects with an otherwise identical description.
- Location - Indicates teh order in which the object appears within the parent window, frame, or dialog box relative to other objects with an otherwise identical description. Values are assigned from top to bottom, and then left to right.
- Web Browser object has the third ordinal identifier type:
CreateTime - Indicates the order in which the browser was opened relative to other open browsers with an otherwise identical description. Each test object class has a default ordinal identifier selected.

SGML
XML is a lightweight cut-down version of SGML which keeps enough of its functionality to make it useful but removes all the operational features which made SGML too complex to program for in a Web environment.
XML is an abbreviated version of SGML, to make it easier to use over the Web, easier for you to define your own document types, and easier for programmers to write programs to handle them.
Wednesday, November 3, 2010
XML Tags
XML Tags begin with <> sign, that is not inside a comment or a CDATA session.
The tags are paired, so that any opening tag must have a closing tag. The end-tags are same as start-tags except that they have a / right after the opening < character.
All of the information from the beginning of the start-tag to the end-tag, and including every thing in between is called an element.
The text between start-tag and end-tag is called the element content.
XML Tag Rules
- All well-formed XML document must have at least one element.
- Maintain case within a tag set.
- XML elements may contain other elements but the nesting of elements must be correct.
- Tags Naming
- Tags should begin with either a letter, an underscore(_) or a colon (:) followed by some combination of letters, numbers, periods (.), colons, underscores, or hyphens (-) but no white space. It is also a good idea to not use colons as the first character in a tag name even if it is legal.
- Names cannot contain spaces.
- Names can't start with the letters xml, in uppercase, lowercase, or mixed. you can't start a name with xml, XML, XmL or any other combination.
- Define Valid Attributes
XML Document Structure
XML Documents have a logical structure. Logically, documents are composed of declarations, elements, comments, character references, and processing instructions, all of which are indicated in the document by explicit markup.
XML Declaration is included as the first line in the document. It defines the XML Version of the document. In this case the document is of 1.0 version.
XML groups information in hierarchies. The items in the document relate to each other in parent/child and sibling/ sibling relationship.
Root element: First element of the document is called Root element. This element is the "the parent" of all other elements.
XML Tree starts at the root and branches to the lowest level of the test.
<root>
<child>
<subchild>...</subchild>
</child>
</root>
The terms parent, child and sibling are used to describe the relationship between elements. Parent elements have children. Children on the same level are called siblings (brothers or sisters).
All XML documents must have a root tag.
XML structure is called tree, and any parts of the tree that contain children are called branches, while parts that have no children are called leaves.
XML Element
The start tag consists of a name surrounded by angle brackets. The end tag consissts of the same name surrounded by angle brackets, but with a slash preceding the name.
XML defines the text between the start and end tag to be "character data"
Tuesday, November 2, 2010
XML Attributes
XML attributes provide additional information about elements. Attributes are always contained within the start tag of an element.
Atttributes are name-value pairs that are separated by an equals sign(=). They may occur inside start-tags or empty tags, but never inside end-tags.
Attributes must have vales - even if that value is just an empty string (such as "") - and those values must be in quotes.
Either single quotes or double quotes are fine, but they have to match.
Example:
<input checked='true'>
or
<input checked="true">
but you can't use
<input checked="true'>
XML Comments
Syntax XML Comments
<!-- This is a comments -->
Rules that needs to be remembered for writing the comments
1. You should never have "-" or "--" within the text of your comment, as it might be confusing the XML processor.
2. Never place a comment within a tag.
3. Never place a comment before the XML Declaration
XML Introduction
XML is actually a meta languague - a language for describing other languages - which lets you design your own markup languages.
XML is sometimes referred to as 'self-describing data' because the names of the markup elements should represent the type of content they hold.
XML Document example
<?xml version="1.0">
<employee>
<name>akhila</name>
<rollno>501</rollno>
</employee>
Common Uses of XML
1. Information Identification
Since you can define your own markup, you can define meaningful names for all your information.
2. Information storage
XML can be used to store textual information across any platform.
3. Information structure
XML can be used to store and identify any kind of (hierarchical) information structure especially for long, deep, or complex document sets or data sources, making it ideal for information management back-end to serving the Web.
4. Publishing
XML has the benefits of robut document management and control (with XML) and publish to the Wen (as HTML) as well as to paper (as PDF) and to other formats (eg., Braille, Audio, etc) from a single source document by using hte appropriate stylesheets.
5. Messaging and Data Transfer
XML is very heavily used for enclosing or encapsulating information in order to pass it between different computing system.
6. Web Services
Because of its use in browsers, machine processable data can be exchanged between consenting system. Weather services, e-commerce sites, AJaX sites and thousands of other data-exchange services use XML for data management and transmission.
7. e-Commerce
Companies are discovering that by communicating via the Internet, instead of by more traditional methods (such as faxing, human-to-human communication, and so on) they can streamline their processes, decreasing costs and increasing response times. Whenever one company needs to send data to another, XML is the perfect format for exchange.
8. Distributed Computing
XML can be used as a means for sending data for distributed computing, where objects on one computer call objects on another computer to do work. There have been numerous standards for distributed computing such as DCOM, CORBA, and RMI/IIOP, but as using XML and HTML through web services and/or SOAP enables this to occur even through a firewall.
Monday, November 1, 2010
CoolTuts - Java - IO
2. Files are created through streams in Java Code
3. A stream is a linear sequential flow of bytes of input and output data.
4. Streams are written to the file system to create files
5. Streams can also be transferred over the internet.
6. There are three types of streams
System.out -- Standard Output Stream
System.in -- Standard Input Stream
System.err -- Standard Error
Java.io package contains large number of classes that deal with Java input and output. Most of the classes consists of
- Byte Streams that are subclasses of InputStream and OutputStream
- Character streams that are subclasses of Reader and Writer
Reader and Writer classes read and write 16-bit Unicode characters. InputStream reads 8-bit bytes, while OutputStream writes 8-bit bytes.
If you use binary data, such as integers or doubles, then use the InputStream and OutputStream classes.
If you are using text data, then Reader and Writer classes are right.
Random Access
RandomAccessFile class permits random access. The data is stored in binary format. Using random access files improves performance and efficiency.
Object or Non-Object
If the data itself is an object, then use the ObjectInputStream and ObjectOutputStream classes.
Sources and sinks for data
You can Input or Output your data in number of ways: sockets, files, strings and arrays of characters.
Any of these can be a source for an InputStream or Reader or sink for an OutputStream or Writer.
Filtering
Buffering Instead of going back to operating system for each byte, you can use an object to provide a buffer.
Checksumming As you are reading or writing a stream, you might want to compute a checksum on it. A checksum is a value you can use later to make sure the stream was transmitted properly.
InputStream classes
In the InputStream class, bytes can be read from three different sources:
1. An array of bytes
2. A file
3. A pipe
Input Stream Methods
1. abstract int read() reads a single byte, an array, or a subarray of bytes. It returns the bytes read, the number of bytes read, or -1 if end-of-file has been reached.
2. read(), which takes the byte array, reads an array or a subarray of bytes and returns a -1 if the end-of-file has been reached.
3. skip(), which takes long, skips a specified number of bytes of input and returns the number of bytes actually skipped.
4. available() returns the number of bytes that can be read without blocking. Both the input and output can block threads until the byte is read or written.
5. close() closes the input stream to free up system resources.